Задачи и условия проекта
Основной задачей проекта было как можно быстрее подготовить корректно задокументированный исходный код. При этом необходимо было учитывать несколько важных условий:
- Исходные файлы на Java, Kotlin и React (TypeScript) должны были быть оформлены в соответствии с отраслевыми стандартами JavaDoc и JSDoc.
- Общий объем кодовой базы составлял около 3200 файлов.
- Ранее документировались только сложные участки кода, однако новое требование было гораздо строже — необходимо было задокументировать весь проект в соответствии со стандартами.
- Для выполнения задачи потребовалось чуть больше двух месяцев.
- При этом кодовая база должна была оставаться полностью конфиденциальной.
Подход
Чтобы успешно справиться со всеми вызовами, наша команда решила использовать современные методы автоматизированного документирования кода с применением искусственного интеллекта:
- Мы выбрали открытую LLM-модель, показавшую отличные результаты при работе с программным кодом.
- Затем провели серию экспериментов с автоматическим документированием отдельных файлов, используя выбранную модель.
- После этого оценили полученные результаты и измерили качество генерируемой документации.
- Далее арендовали сервер с мощным GPU, разработали приложение для автоматического документирования файлов и протестировали его работу.
- На заключительном этапе приложение было запущено для обработки всей кодовой базы.
Реализация
На первом этапе мы провели тестовое автоматическое документирование кода с использованием шести открытых моделей: Gemma3, Deepseek-r1, Phi4, Llama3.3, Codellama и Qwen 2.5 coder. После сравнения результатов всех моделей мы выбрали Qwen 2.5 coder 32B как наиболее точную и производительную.
Затем был подобран провайдер GPU-хостинга. Для запуска полной версии модели Qwen 2.5 требовалось значительное количество видеопамяти — около 65 ГБ.
Графический процессор Nvidia H100 с объёмом памяти 80 ГБ отлично справился с задачей, обеспечив скорость генерации около 30–50 токенов в секунду.
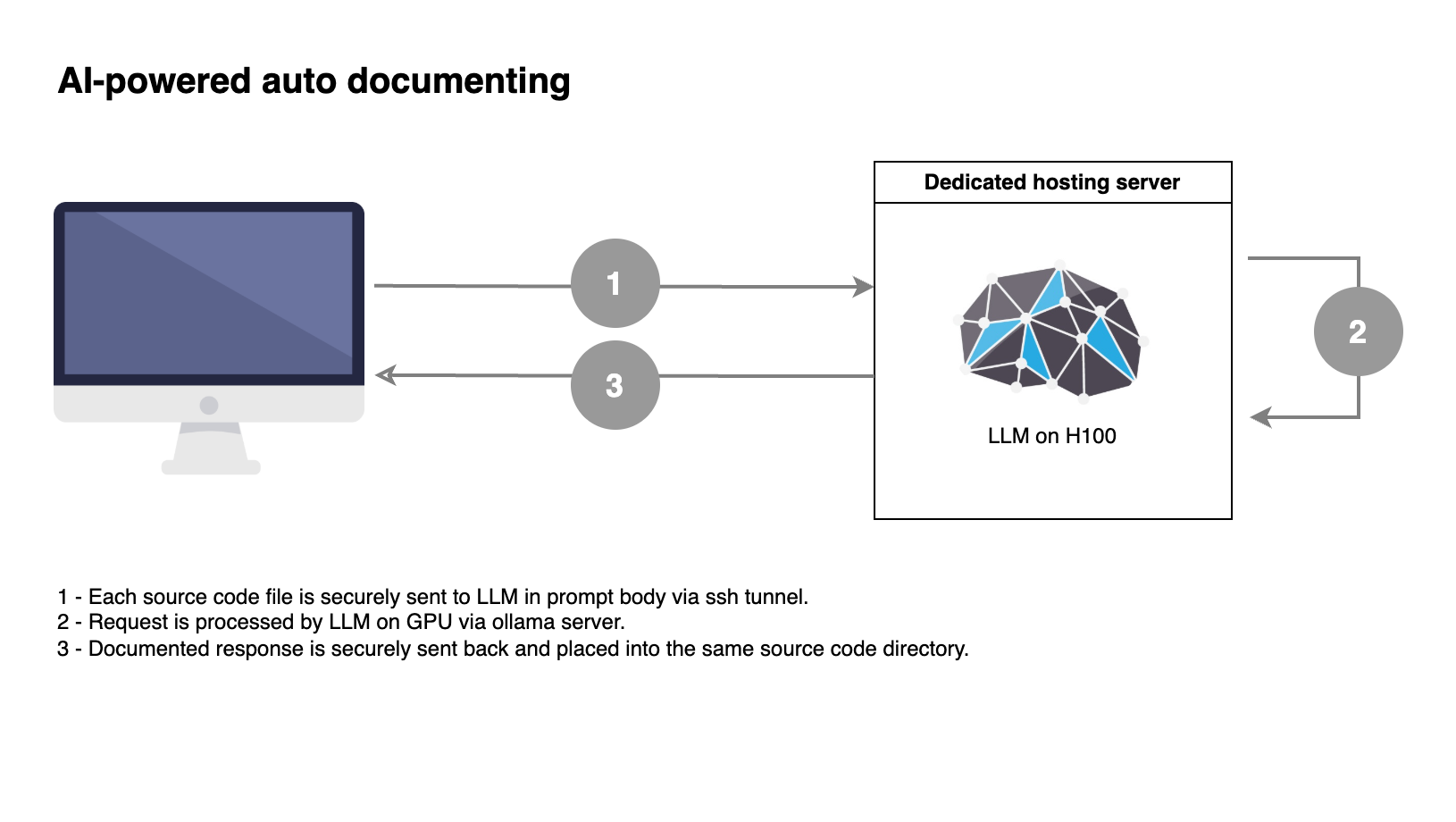
На следующем этапе мы разработали приложение, которое взаимодействовало с сервером Ollama и выполняло автоматическое документирование исходных файлов.
Были сформированы несколько оптимизированных промптов, хорошо работающих с файлами на Java, Kotlin и TypeScript. Приложение фиксировало каждую попытку генерации, собирало статистику и функционировало в отказоустойчивом режиме.
Далее был проведен основной запуск. Модель LLM для документирования кода обработала всю кодовую базу примерно за 10 часов. Часть процесса выполнялась параллельно на двух станциях с GPU Nvidia H100.
Перед этим мы убедились, что транспортный канал защищён, а удаленная система не хранит никаких логов, что полностью соответствовало требованиям по безопасности данных.
Иллюстрация
Ключевые особенности
- Автоматическое документирование исходного кода на Java, Kotlin и TypeScript с использованием технологий искусственного интеллекта
- Используемая LLM-модель: Qwen 2.5 coder 32B, работающая через Ollama на GPU H100
- Более 3000 файлов задокументированы примерно за 10 часов
- Бюджет на хостинг: около 25 долларов
Результаты
Благодаря использованию подхода на базе искусственного интеллекта и современных инструментов автоматического документирования кода, команда достигла следующих результатов:
- Быстро задокументировала всю кодовую базу, применив модель LLM, развёрнутая по принципу “as-a-service”.
- Обеспечила безопасное выполнение процессов благодаря выделенному GPU-хостингу.
- Сократила затраты на документирование примерно в 30 раз по сравнению с ручной работой.
- Создала качественную и структурированную документацию кода в соответствии со стандартами JavaDoc и JSDoc.