
Сегодня рынок искусственного интеллекта предлагает широкий выбор больших языковых моделей (LLM) — как с открытым, так и с закрытым исходным кодом, каждая из которых обладает своими уникальными возможностями.
Некоторые из этих моделей уже значительно превосходят другие (например, ChatGPT, Gemini, Claude, Llama и Mistral), поскольку они способны решать задачи быстрее и точнее.
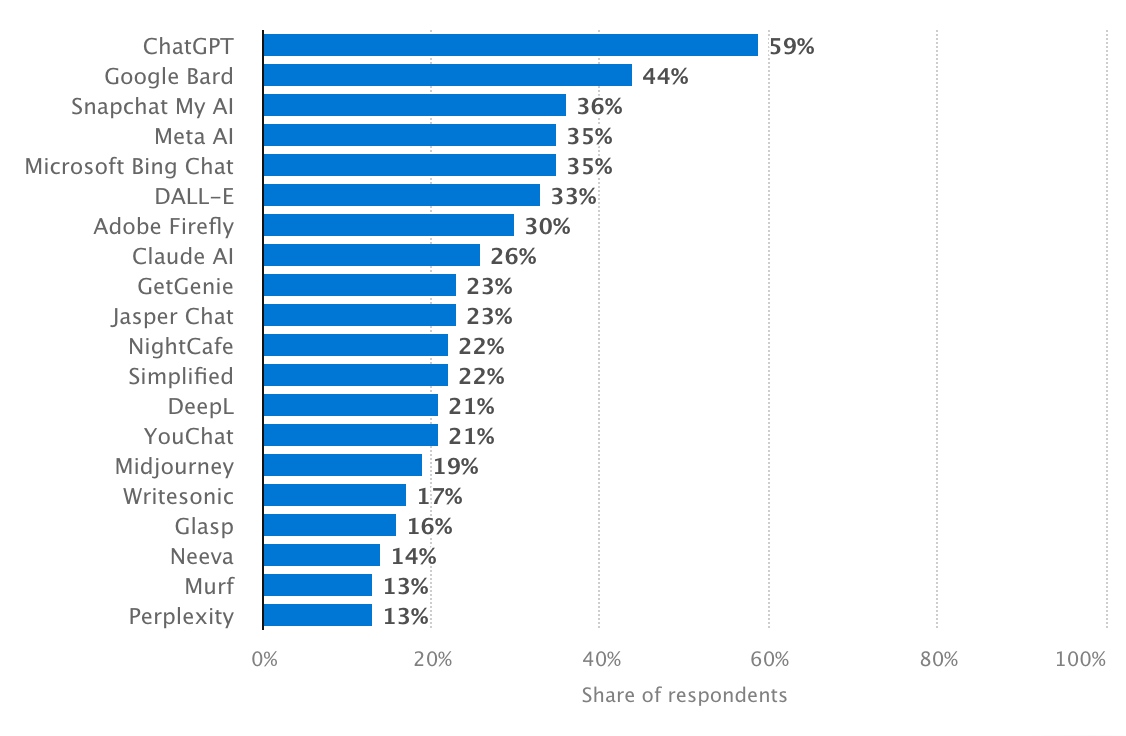
Самые популярные инструменты ИИ, Statista
Но даже самые продвинутые модели, какими бы мощными они ни были, не всегда идеально работают с самого начала. Многие компании быстро замечают, что универсальные LLM не учитывают узкоспециализированную терминологию, внутренние процессы или фирменный стиль. Именно здесь на помощь приходит настройка моделей.
Что такое настройка языковой модели и зачем она нужна в 2025 году
Тонкая настройка LLM (fine-tuning) — это процесс продолжения обучения уже готовой LLM с использованием небольшого специализированного набора данных, который связан с конкретной задачей, отраслью или организацией.
Тонкая настройка LLM отличается от обучения с нуля, поскольку она включает в себя только дообучение модели на узкоспециализированных данных, чтобы она лучше понимала определенную область или действовала по конкретным стандартам.
Почему предварительно обученных моделей не всегда достаточно
Предварительно обученные языковые модели создаются для решения широкого круга задач — от генерации текста и перевода до суммирования и ответа на вопросы. Однако в ряде случаев им не хватает точности в деталях.

Поскольку такие модели обучаются на общедоступных интернет-данных, они могут некорректно интерпретировать профессиональную лексику — например, юридические термины, финансовую отчетность или медицинскую документацию.
Безусловно, ответы таких моделей могут казаться вполне приемлемыми, но для экспертов в конкретных сферах они нередко выглядят запутанными или ошибочными.
Именно здесь на помощь приходит тонкая настройка LLM. К примеру, больница может адаптировать модель так, чтобы она точно понимала медицинскую терминологию и специфику коммуникации между врачами.
Или логистическая компания может обучить модель понимать все тонкости доставки и учета товаров.
Преимущества тонкой настройки LLM для бизнеса
Тонкая настройка больших языковых моделей позволяет компаниям максимально эффективно использовать ИИ, направляя его на выполнение именно тех задач, которые им необходимы.
Прежде всего, тонкая настройка модели позволяет ей «говорить» на языке вашей компании. Каждый бизнес имеет свой стиль общения — одни компании используют формальный и технический язык, другие — более дружелюбный и теплый. С помощью управляемой настройки модель учит ваш стиль и использует ваши предпочтительные выражения.
Кроме того, тонкая настройка значительно повышает точность в специализированных областях. Например, модель OpenAI o1 на март 2024 года показала наивысший результат в 94,8% при решении математических задач.
Однако, как универсальная модель, она может не полностью понимать юридическую терминологию, медицинские формулировки или экономические выражения.
Но если модель настраивается с использованием данных из определенной отрасли, она значительно лучше обучается обрабатывать и отвечать на сложные или технические вопросы.
Приватность — ещё одна важная причина, по которой компании предпочитают тонкую настройку LLM. Вместо передачи конфиденциальных данных сторонним сервисам, организации настраивают модели непосредственно на своих серверах, обеспечивая таким образом защиту информации и соблюдение требований безопасности.
Наконец, тонкая настройка LLM может сэкономить деньги в долгосрочной перспективе. Хотя на начальном этапе это требует времени и усилий, настроенная модель выполняет задачи быстрее и более компетентно.
Она уменьшает количество ошибок, сокращает число повторных запросов и зачастую обходится дешевле, чем частое использование платных API универсальных моделей.
Топ методов тонкой настройки LLM в 2025 году
Тонкая настройка LLM в 2025 году стала более доступной и удобной, чем когда-либо. Организациям больше не нужны огромные бюджеты или глубокие знания в области машинного обучения для того, чтобы адаптировать модель под свои нужды.

Сегодня доступно множество проверенных подходов — от легкой настройки до полного переобучения, что даёт возможность подобрать оптимальный метод в зависимости от задач, доступных данных и инфраструктуры.
Полная настройка — самый эффективный метод
Полная настройка определяется IBM как метод, при котором используется предварительное знание базовой модели в качестве отправной точки для ее доработки с использованием меньшего, специализированного набора данных.
Весь процесс настройки изменяет веса параметров модели, которые были заранее определены в ходе предыдущего обучения, чтобы адаптировать модель под конкретную задачу.
LoRA и PEFT
Если вы хотите что-то быстрее и дешевле, стоит обратить внимание на LoRA (Low-Rank Adaptation) и PEFT (Parameter-Efficient Fine-Tuning).
Эти методы изменяют лишь отдельные части модели, а не всю её целиком. Они эффективно работают даже при ограниченном объёме специализированных данных и ресурсов, что делает их подходящим выбором для стартапов и компаний среднего масштаба.
Настройка по инструкциям
Еще один подход — настройка модели на выполнение инструкций. Этот метод помогает ИИ точнее понимать, как именно следует выполнять задачи, и формулировать краткие, прикладные ответы. Такой подход хорошо подходит для ИИ-ассистентов, используемых в поддержке, обучении или консультациях.
RLHF (Обучение с подкреплением на основе обратной связи от человека)
RLHF (Reinforcement Learning from Human Feedback) предназначен для интенсивного использования. Этот метод обучает модель, предоставляя ей примеры правильных и неправильных ответов, и поощряет оптимальные ответы.
RLHF является более прогрессивным и сложным методом, но отлично подходит для создания высококачественного и надежного ИИ, например, для юрисконсультов или экспертных советников.
Prompt-Tuning и адаптеры
Если вам нужен быстрый и простой способ адаптировать модель, можно использовать prompt-tuning или адаптеры. Эти методы не затрагивают всю модель, а вместо этого используют небольшие дополнения или умные подсказки, чтобы направить поведение модели. Они быстрые, дешевые и легко реализуемые.
| Метод | Что делает | Стоимость/Скорость | Лучше всего для |
| Полная настройка | Обучает всю модель на новых данных | Высокая / Медленная | Масштабные проекты, высокие требования к производительности |
| LoRA / PEFT | Настраивает только выбранные параметры | Низкая / Быстрая | Стартапы, команды с ограниченными ресурсами |
| Настройка по инструкциям | Улучшает отклик на команды пользователя | Средняя / Умеренная | ИИ-помощники, боты поддержки |
| RLHF | Обучает с использованием обратной связи от человека и сигналов вознаграждения | Высокая / Умеренная | Экспертные системы, безопасные и надежные ответы |
| Prompt/Адаптеры | Добавляет небольшие модули или подсказки, без переобучения | Очень низкая / Очень быстрая | Быстрое тестирование, недорогая кастомизация |
Лучшие методы настройки моделей в 2025 году – Обзор
Что нужно для тонкой настройки LLM в 2025 году
Тонкая настройка LLM в 2025 году стала доступной даже для компаний без команды специалистов по машинному обучению. Однако для достижения точных и надежных результатов важно правильно подойти к этому процессу.
Первый шаг — выбрать тип модели: открытые или закрытые. Открытые модели (например, LLaMA, Mistral) предлагают больше возможностей: вы можете разместить их на своих серверах, настроить архитектуру модели и управлять данными.
Закрытые модели (например, GPT или Claude) обеспечивают высокую мощность и качество, но работают через API, то есть полный контроль над ними недоступен.
Если для вашей компании приоритетом являются безопасность данных и возможность гибкой настройки, стоит обратить внимание на открытые модели. А если важны быстрое внедрение и минимальные технические сложности, более подходящим выбором могут стать закрытые решения.
Следующий шаг — подготовка данных для обучения. Это должны быть хорошо организованные примеры из вашей области, такие как электронные письма, чаты поддержки, документы или другие тексты, с которыми работает ваша компания.
Чем лучше качество ваших данных, тем точнее станет модель после настройки. Без надежных и релевантных данных она может формулировать ответы красиво, но при этом допускать ошибки или не улавливать суть задачи.

Кроме того, вам понадобятся правильные инструменты и инфраструктура. Некоторые компании используют платформы AWS или Google Cloud, другие предпочитают размещать все локально для дополнительной конфиденциальности. Для управления процессом обучения можно использовать инструменты, такие как Hugging Face или Weights & Biases.
Конечно, весь процесс не сработает без нужных людей. Обычно в настройке участвуют инженеры по машинному обучению (для обучения модели), специалисты DevOps (для настройки и запуска систем) и бизнес-аналитики (для объяснения, чему модель должна научиться).
Если у вас нет такой команды, создание ее с нуля может быть дорогим и медленным процессом. Поэтому многие компании сегодня сотрудничают с аутсорсинговыми компаниями, которые специализируются на разработке кастомного ПО с использованием ИИ.
Аутсорсинговые компании могут взять на себя всю техническую сторону, начиная от выбора модели и подготовки данных и заканчивая обучением, тестированием и развертыванием.
Бизнес-применения для тонко настроенных LLM
Тонко настроенные LLM становятся не просто умнее, а действительно полезными для решения реальных бизнес-задач. Обученная на данных вашей компании, модель начинает «понимать» контекст и особенности вашей работы, что позволяет ей выдавать точные результаты вместо общих и малоинформативных ответов.
Агенты поддержки клиентов на базе ИИ
Вместо универсального чат-бота, вы можете создать агента поддержки, который хорошо знаком с вашими услугами, продуктами и политиками. Он будет отвечать так, как если бы это был обученный человеческий агент, но с правильным тоном и актуальной информацией.
Персонализированные виртуальные помощники
Тонко настроенная LLM может помочь с конкретными задачами, такими как обработка заказов, ответы на вопросы HR, организация собеседований или отслеживание посылок. Эти помощники учатся на ваших внутренних документах и системах, поэтому знают, как выполняются задачи в вашей компании.
Управление знаниями в крупных компаниях
В больших компаниях и предприятиях слишком много документов, инструкций и корпоративных политик, чтобы запомнить их все.
Оптимизированная LLM может прочитать их все и предоставить сотрудникам простые ответы всего за несколько секунд. Это экономит время и позволяет находить нужную информацию без необходимости рыться в файлах или PDF-документах.
Специализированные помощники (для права, медицины, электронной торговли)
Узкоспециализированные помощники могут существенно облегчить повседневную работу профессионалов:
- Юристы получают поддержку при анализе контрактов и составлении кратких сводок по судебным делам.
- Врачи используют модель для оформления медицинских записей и быстрого обзора истории болезни пациента.
- Команды в сфере электронной коммерции автоматизируют создание описаний товаров, обновление каталогов и анализ клиентских отзывов.
Пример: Умный путеводитель
Одним из лучших примеров тонкой настройки LLM является умный путеводитель на базе ИИ. Модель была настроена для того, чтобы помогать путешественникам, предоставляя персонализированные советы, основанные на их предпочтениях, местоположении и местных событиях. Вместо того чтобы предлагать общие рекомендации, она создает индивидуальные маршруты и советы.

Трудности при тонкой настройке LLM
В целом, тонкая настройка LLM крайне полезна, но иногда она сопряжена с определенными трудностями.
Первая и самая серьезная проблема — это наличие достаточного объема данных. Настроить модель можно только в том случае, если у вас есть множество структурированных и ценных примеров для обучения.
Если ваш набор данных неорганизован, неполный или содержит ошибки, модель может не научиться тому, что вам действительно нужно. Проще говоря, если вы дадите модели некачественные данные, она будет генерировать некачественные результаты, сколько бы высокоразвита она ни была.
Далее, конечно, стоит учитывать расходы на обучение и поддержку модели. Эти модели требуют огромных вычислительных мощностей, особенно если они большие.
Но затраты не заканчиваются на этапе обучения. Также нужно будет провести тестирование, внести корректировки и убедиться, что модель работает удовлетворительно в долгосрочной перспективе.
Еще одна проблема — это переобучение, когда модель слишком точно запоминает ваши тренировочные данные и не может адекватно реагировать на новые или немного измененные запросы. Она может показывать отличные результаты на тестах, но ломаться, если кто-то задаст ей немного другой вопрос.
Юридические и этические аспекты также играют важную роль. Если модель выдает рекомендации, обрабатывает конфиденциальные данные или участвует в принятии решений, важно проявлять особую осторожность.
Необходимо убедиться, что она не демонстрирует предвзятости, не генерирует вредоносный контент и соответствует требованиям законодательства о защите данных, таким как GDPR или HIPAA.
Как начать тонкую настройку LLM
Если вы планируете настроить модель, то вам повезло: с правильным подходом этот процесс может быть не только простым, но и весьма эффективным.
Первое, что нужно сделать — это оценить вашу бизнес-задачу. Задайте себе вопрос: действительно ли вам нужна тонкая настройка модели, или может быть, достаточно использовать проектирование запросов (создание умных и более детализированных запросов)? Для многих простых задач или областей проектирование запросов будет быстрее и дешевле.
Однако если вы работаете с профессиональной терминологией, строгими требованиями или конфиденциальными данными, тонкая настройка модели может стать гораздо более эффективным решением на долгосрочную перспективу.
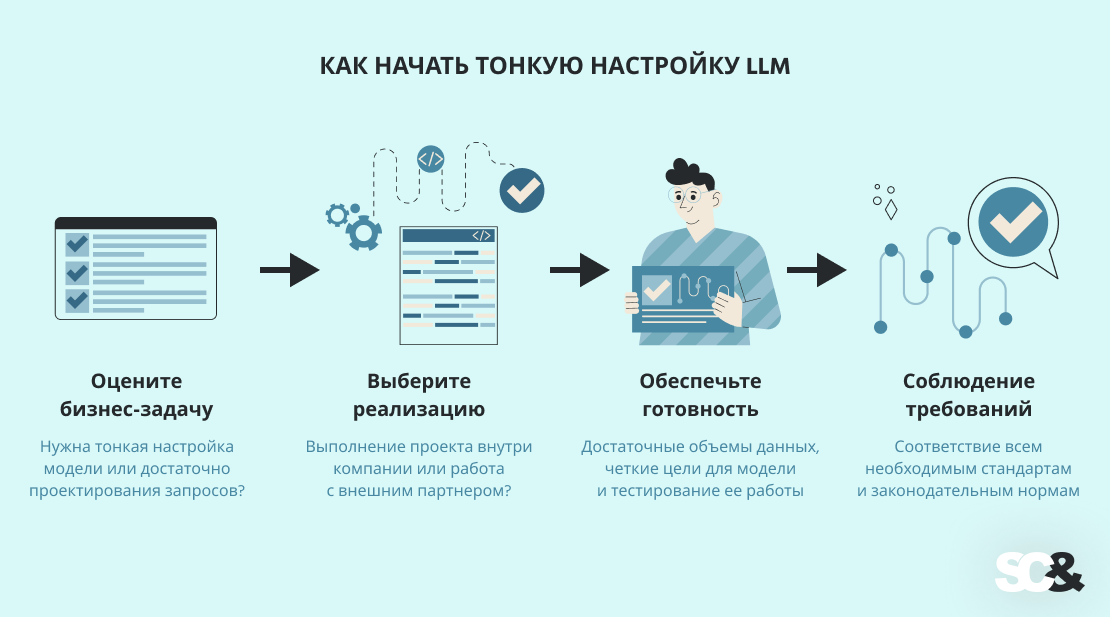
Далее определите, будете ли вы выполнять проект внутри компании или работать с внешним партнером. Создание собственной команды ИИ дает вам полный контроль, но это требует времени, бюджета и специализированных специалистов.
С другой стороны, аутсорсинговый партнер, такой как СКЭНД, может полностью взять на себя техническую часть. Он поможет выбрать подходящую модель, подготовить и настроить данные, развернуть модель и даже помочь с проектированием запросов.
Прежде чем начать, убедитесь, что ваша компания готова. Вам понадобятся достаточные объемы правильных данных, четкие цели для модели и способы тестирования ее работы.
Наконец, не забывайте о защите данных и соблюдении нормативных требований. Если ваша модель будет работать с конфиденциальными, юридическими или медицинскими данными, она должна соответствовать всем необходимым стандартам и законодательным нормам.
Как СКЭНД может помочь
Если у вас нет времени или технической команды для настройки модели внутри компании, СКЭНД возьмет на себя весь процесс.
Мы поможем вам выбрать подходящую модель ИИ для вашего бизнеса (открытые, такие как LLaMA или Mistral, или закрытые, как GPT или Claude). Затем мы подготовим ваши данные, чтобы они были готовы к использованию.
После этого мы сделаем все остальное: настроим модель, развернем ее в облаке или на ваших серверах и будем отслеживать ее производительность, гарантируя, что она работает корректно и эффективно.
Если вам нужна дополнительная защита, мы также предоставляем локальный хостинг для обеспечения безопасности ваших данных и соблюдения всех норм, или вы можете заказать разработку LLM для получения модели ИИ, созданной исключительно для вас.
Часто задаваемые вопросы
Что такое тонкая настройка модели LLM?
Тонкая настройка LLM — это процесс, при котором предварительно обученная языковая модель дообучается на ваших данных, чтобы она лучше усваивала терминологию вашей отрасли, язык или фирменный стиль.
Разве я не могу оставить предварительно обученную модель как есть?
Можете, но предварительно обученные модели являются универсальными и могут плохо справляться с узкоспециализированными темами или с определенной подачей. Тонкая настройка модели позволяет откалибровать ее для точности и актуальности в соответствии с вашими требованиями.
Сколько данных нужно для тонкой настройки модели?
Это зависит от ваших потребностей и размера модели. Чем больше качественных и правильно размеченных данных, тем лучше будут результаты.
Тонкая настройка модели — это дорого?
Тонкая настройка может быть дорогой, особенно для больших моделей, и требует поддержки со временем. Однако в целом она оправдывает себя за счет снижения зависимости от дорогих API-запросов и улучшения пользовательского опыта.